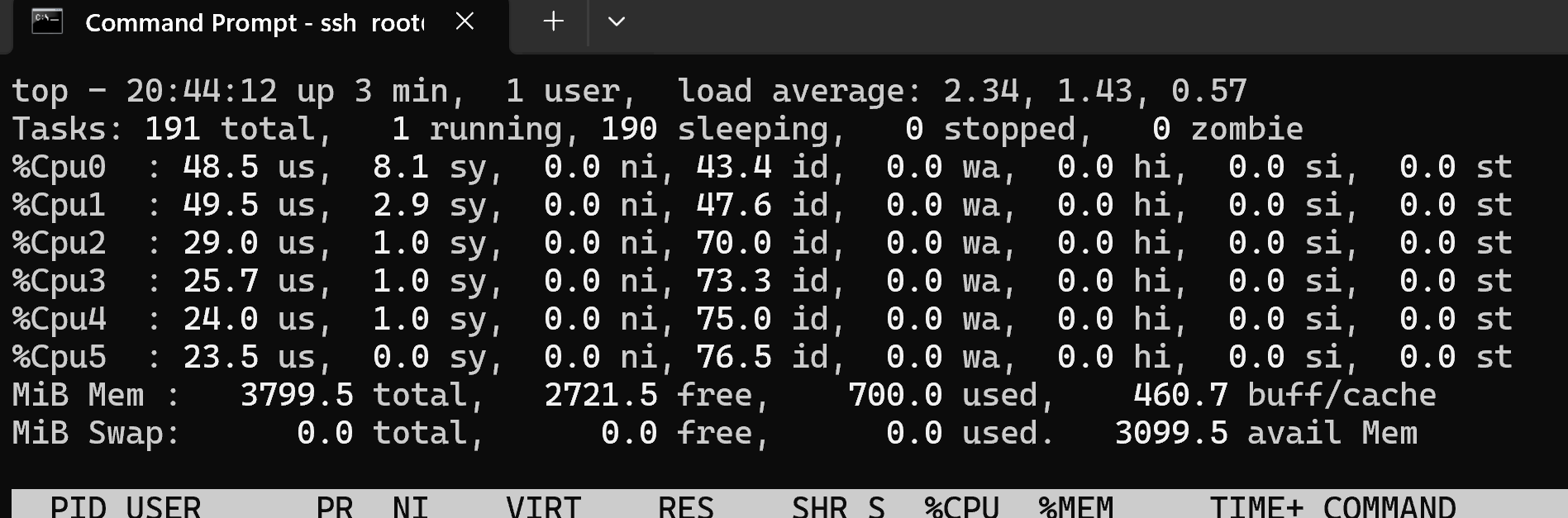
AM6B+ eMMC install:
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 6
On-line CPU(s) list: 0-5
Vendor ID: ARM
Model name: Cortex-A53
Model: 4
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
Stepping: r0p4
CPU(s) scaling MHz: 100%
CPU max MHz: 1800.0000
CPU min MHz: 500.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32
Model name: Cortex-A73
Model: 2
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Stepping: r0p2
CPU(s) scaling MHz: 100%
CPU max MHz: 2208.0000
CPU min MHz: 500.0000
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32
Caches (sum of all):
L1d: 192 KiB (6 instances)
L1i: 320 KiB (6 instances)
L2: 1.3 MiB (2 instances)
Several hours of use after a day of having the updated dtb. Still haven’t noticed any thing broken, no crashes noticed, logs seem as clean as normal.
Some anecdotal numbers. Boot, feels maybe 5-10% faster. Initial skin (Nimbus) load, feels 10-20% faster. Initial widget loading, 20-30% faster. Subsequent widget loading, 30-40% faster. Addon activity  , feels about the same with my settings, but it wasn’t noticeably slow to me before. Clicking around menus, feels 20-30% faster. Menus in addons like YouTube feel particularly faster.
, feels about the same with my settings, but it wasn’t noticeably slow to me before. Clicking around menus, feels 20-30% faster. Menus in addons like YouTube feel particularly faster.
Playback seems smooth. Playing a big 100GB remux (2160p, h265, DTS HD):
top - 03:57:54 up 23:20, 1 user, load average: 0.88, 0.93, 0.94
Tasks: 177 total, 1 running, 176 sleeping, 0 stopped, 0 zombie
%Cpu0 : 16.6 us, 7.0 sy, 0.7 ni, 75.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 7.7 us, 2.7 sy, 0.3 ni, 89.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.7 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.7 sy, 0.3 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3799.5 total, 1268.8 free, 1937.1 used, 672.7 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1862.4 avail Mem
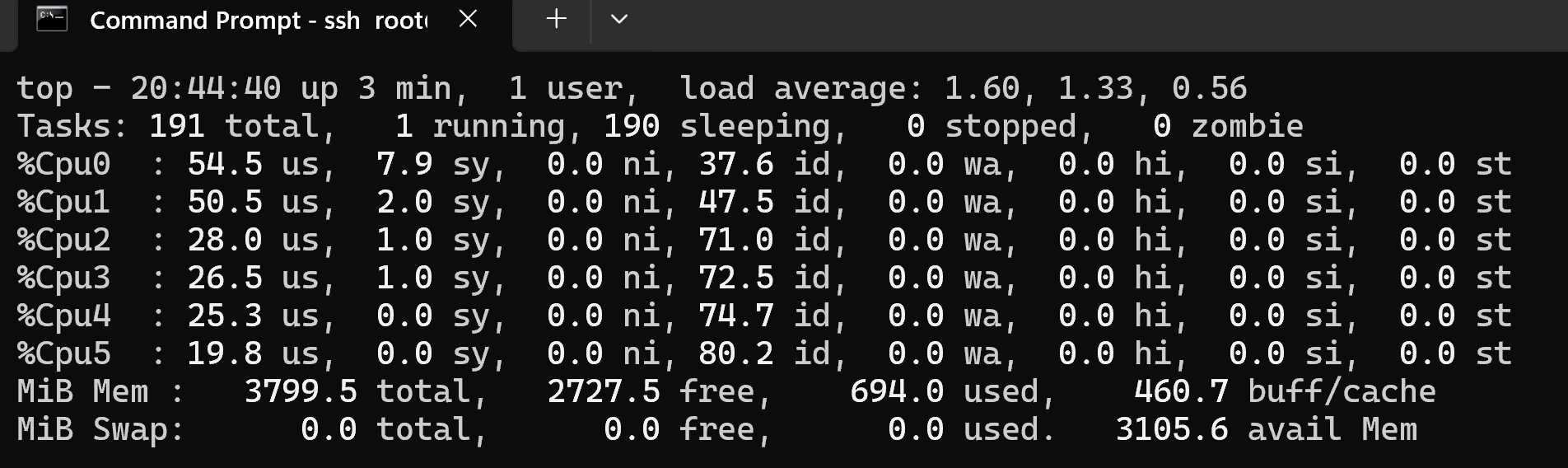
Clicking around menus and widgets:
top - 04:08:36 up 23:30, 1 user, load average: 1.43, 1.08, 1.03
Tasks: 176 total, 2 running, 174 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 5.5 sy, 34.3 ni, 59.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.7 us, 11.1 sy, 29.7 ni, 56.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 22.8 us, 3.6 sy, 3.6 ni, 70.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 15.8 us, 2.0 sy, 6.4 ni, 75.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 8.6 us, 1.7 sy, 8.3 ni, 81.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 17.4 us, 2.0 sy, 3.7 ni, 76.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3799.5 total, 2017.3 free, 1186.3 used, 675.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2613.3 avail Mem
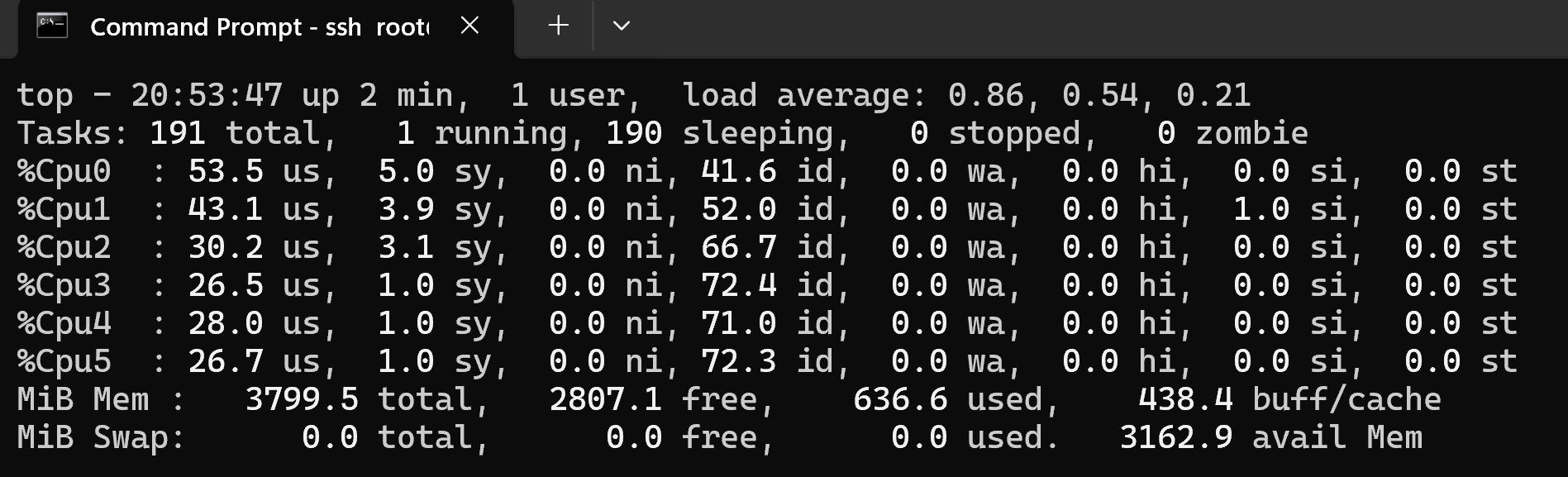
Live stream on YouTube addon (720p, h264):
top - 04:13:38 up 23:35, 1 user, load average: 2.08, 1.55, 1.21
Tasks: 181 total, 1 running, 180 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 1.3 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 18.7 us, 6.7 sy, 0.0 ni, 74.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 32.9 us, 11.0 sy, 0.0 ni, 56.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 23.2 us, 11.3 sy, 0.3 ni, 65.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 1.3 us, 2.0 sy, 0.3 ni, 96.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3799.5 total, 2277.0 free, 646.6 used, 955.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3153.0 avail Mem
Pretty happy with this change. Between the spectrum of Kodi on Android on a shield being a 0 and Kodi on x86 on something like an i5 Nuc being a 10. Previous in terms of interface speed was about 4, this is about a 6+. Continues to be well done! If there’s more empirical data that would be useful definitely shout it out, happy to help provide where I can.