Thanks for clarification with scaling factor, now values somehow fit together:
Beelink statement: A73: 4.8 DMIPS/Mhz A53: 2.3 DMIPS/Mhz
Your measurement: A73: 4.3 DMIPS/Mhz A53: 2.6 DMIPS/Mhz
But in the end it’s the ratio between the cores which matters.
Just out of curiosity, could you redo the test with old DTB (without cache optimization), to see if there was an impact on core performance?
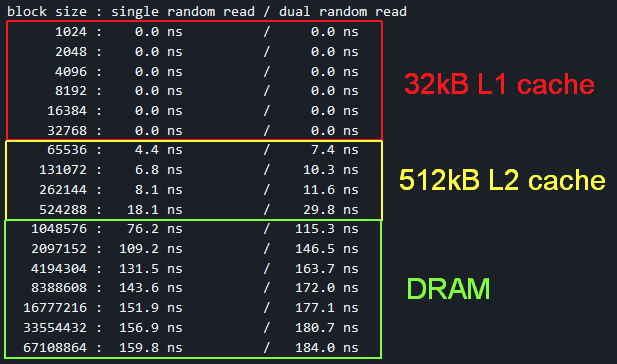
Repeating with the old DTB (no cache nodes or capacity properties)
A53 - 8694140.0 (~0.03% change)
A73 - 16661113.0 (~0.05% change)
It’s amazing how consistent the test results are. There’s no difference with or without the DTB changes, but to be fair I don’t think we would expect a difference in this sort of benchmark.
Thanks for your quick retesting, so no significance by Dhrystone.
So either the cache was already active before optimizations (with the bug of unified L2), or Dhrystone mainly runs in internal L1 and is the wrong benchmark for cache. Memtest comparison would give the ultimate answer.
As with lmbench, tinymembench only runs on one core at a time. There were no differences more than 1% between the original DTB and DTB with cache changes, for either A53 or A73 cores.
There’s so many numbers with this test that I’m not sure which would be the most relevant?
Very nice, many thanks for testing
Maybe you can share the complete results.
Regarding Cache, it’s the Memory latency test, where you can see if cache is present, and which size:
But also the Memory bandwidth tests => C fill values are of interest, as there was also a discussion about DDR Clock / Bandwith (some read values as low as ~300MHz, but LPDDR also has dynamic clock switching feature)
CoreELEC:~/downloads # taskset -c 0-1 ./tinymembench
tinymembench v0.4 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for 'copy' tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source -> L1 cache, L1 cache -> destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
==========================================================================
C copy backwards : 1752.6 MB/s
C copy backwards (32 byte blocks) : 1621.1 MB/s (1.0%)
C copy backwards (64 byte blocks) : 1749.0 MB/s
C copy : 1753.7 MB/s
C copy prefetched (32 bytes step) : 1885.7 MB/s
C copy prefetched (64 bytes step) : 1883.5 MB/s
C 2-pass copy : 1344.3 MB/s (0.1%)
C 2-pass copy prefetched (32 bytes step) : 1207.2 MB/s
C 2-pass copy prefetched (64 bytes step) : 1227.7 MB/s
C fill : 6667.2 MB/s
C fill (shuffle within 16 byte blocks) : 6664.0 MB/s
C fill (shuffle within 32 byte blocks) : 5357.8 MB/s
C fill (shuffle within 64 byte blocks) : 1825.6 MB/s
---
standard memcpy : 1705.0 MB/s (0.7%)
standard memset : 7157.9 MB/s
---
NEON read : 2319.0 MB/s (0.4%)
NEON read prefetched (32 bytes step) : 3926.9 MB/s
NEON read prefetched (64 bytes step) : 3928.7 MB/s
NEON read 2 data streams : 2049.7 MB/s
NEON read 2 data streams prefetched (32 bytes step) : 3624.8 MB/s
NEON read 2 data streams prefetched (64 bytes step) : 3625.3 MB/s
NEON copy : 1771.7 MB/s (0.2%)
NEON copy prefetched (32 bytes step) : 1922.6 MB/s
NEON copy prefetched (64 bytes step) : 1924.6 MB/s
NEON unrolled copy : 1784.6 MB/s (0.2%)
NEON unrolled copy prefetched (32 bytes step) : 2048.7 MB/s
NEON unrolled copy prefetched (64 bytes step) : 2046.6 MB/s
NEON copy backwards : 1765.0 MB/s
NEON copy backwards prefetched (32 bytes step) : 1885.8 MB/s
NEON copy backwards prefetched (64 bytes step) : 1890.2 MB/s (0.1%)
NEON 2-pass copy : 1623.3 MB/s
NEON 2-pass copy prefetched (32 bytes step) : 1728.9 MB/s
NEON 2-pass copy prefetched (64 bytes step) : 1729.8 MB/s
NEON unrolled 2-pass copy : 1574.1 MB/s
NEON unrolled 2-pass copy prefetched (32 bytes step) : 1859.4 MB/s
NEON unrolled 2-pass copy prefetched (64 bytes step) : 1933.3 MB/s
NEON fill : 7167.7 MB/s
NEON fill backwards : 7170.6 MB/s
VFP copy : 1788.4 MB/s (0.2%)
VFP 2-pass copy : 1598.7 MB/s
ARM fill (STRD) : 4921.1 MB/s
ARM fill (STM with 8 registers) : 7159.1 MB/s
ARM fill (STM with 4 registers) : 7013.0 MB/s
ARM copy prefetched (incr pld) : 1920.5 MB/s
ARM copy prefetched (wrap pld) : 1872.9 MB/s
ARM 2-pass copy prefetched (incr pld) : 1638.3 MB/s
ARM 2-pass copy prefetched (wrap pld) : 1633.0 MB/s
==========================================================================
== Framebuffer read tests. ==
== ==
== Many ARM devices use a part of the system memory as the framebuffer, ==
== typically mapped as uncached but with write-combining enabled. ==
== Writes to such framebuffers are quite fast, but reads are much ==
== slower and very sensitive to the alignment and the selection of ==
== CPU instructions which are used for accessing memory. ==
== ==
== Many x86 systems allocate the framebuffer in the GPU memory, ==
== accessible for the CPU via a relatively slow PCI-E bus. Moreover, ==
== PCI-E is asymmetric and handles reads a lot worse than writes. ==
== ==
== If uncached framebuffer reads are reasonably fast (at least 100 MB/s ==
== or preferably >300 MB/s), then using the shadow framebuffer layer ==
== is not necessary in Xorg DDX drivers, resulting in a nice overall ==
== performance improvement. For example, the xf86-video-fbturbo DDX ==
== uses this trick. ==
==========================================================================
NEON read (from framebuffer) : 66.3 MB/s
NEON copy (from framebuffer) : 64.4 MB/s
NEON 2-pass copy (from framebuffer) : 65.3 MB/s
NEON unrolled copy (from framebuffer) : 64.5 MB/s
NEON 2-pass unrolled copy (from framebuffer) : 64.9 MB/s
VFP copy (from framebuffer) : 404.0 MB/s
VFP 2-pass copy (from framebuffer) : 396.3 MB/s
ARM copy (from framebuffer) : 222.3 MB/s
ARM 2-pass copy (from framebuffer) : 223.3 MB/s
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can't handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
==========================================================================
block size : single random read / dual random read
1024 : 0.0 ns / 0.0 ns
2048 : 0.0 ns / 0.0 ns
4096 : 0.0 ns / 0.0 ns
8192 : 0.0 ns / 0.0 ns
16384 : 0.0 ns / 0.0 ns
32768 : 0.0 ns / 0.0 ns
65536 : 3.6 ns / 6.1 ns
131072 : 5.5 ns / 8.5 ns
262144 : 7.3 ns / 10.8 ns
524288 : 69.3 ns / 107.9 ns
1048576 : 106.3 ns / 143.0 ns
2097152 : 125.3 ns / 154.8 ns
4194304 : 138.4 ns / 162.9 ns
8388608 : 145.3 ns / 167.1 ns
16777216 : 149.6 ns / 170.2 ns
33554432 : 152.3 ns / 172.5 ns
67108864 : 165.6 ns / 196.2 ns
A73 core
Summary
CoreELEC:~/downloads # taskset -c 2-5 ./tinymembench
tinymembench v0.4 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for 'copy' tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source -> L1 cache, L1 cache -> destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
==========================================================================
C copy backwards : 3520.9 MB/s
C copy backwards (32 byte blocks) : 3516.7 MB/s
C copy backwards (64 byte blocks) : 3523.5 MB/s
C copy : 3534.5 MB/s
C copy prefetched (32 bytes step) : 3488.8 MB/s
C copy prefetched (64 bytes step) : 3518.0 MB/s
C 2-pass copy : 2665.9 MB/s
C 2-pass copy prefetched (32 bytes step) : 2672.2 MB/s
C 2-pass copy prefetched (64 bytes step) : 2709.3 MB/s
C fill : 6496.1 MB/s
C fill (shuffle within 16 byte blocks) : 6491.4 MB/s
C fill (shuffle within 32 byte blocks) : 6490.4 MB/s
C fill (shuffle within 64 byte blocks) : 6490.6 MB/s
---
standard memcpy : 3535.3 MB/s
standard memset : 6183.4 MB/s
---
NEON read : 7807.5 MB/s
NEON read prefetched (32 bytes step) : 7758.2 MB/s
NEON read prefetched (64 bytes step) : 7802.2 MB/s
NEON read 2 data streams : 7612.3 MB/s
NEON read 2 data streams prefetched (32 bytes step) : 7449.4 MB/s (0.3%)
NEON read 2 data streams prefetched (64 bytes step) : 7593.2 MB/s (0.2%)
NEON copy : 3552.4 MB/s
NEON copy prefetched (32 bytes step) : 3503.1 MB/s
NEON copy prefetched (64 bytes step) : 3539.3 MB/s
NEON unrolled copy : 3553.3 MB/s
NEON unrolled copy prefetched (32 bytes step) : 3285.5 MB/s (0.2%)
NEON unrolled copy prefetched (64 bytes step) : 3408.4 MB/s (0.4%)
NEON copy backwards : 3533.9 MB/s (0.1%)
NEON copy backwards prefetched (32 bytes step) : 3484.0 MB/s
NEON copy backwards prefetched (64 bytes step) : 3518.0 MB/s
NEON 2-pass copy : 3127.8 MB/s
NEON 2-pass copy prefetched (32 bytes step) : 2964.4 MB/s
NEON 2-pass copy prefetched (64 bytes step) : 2979.9 MB/s
NEON unrolled 2-pass copy : 3118.3 MB/s
NEON unrolled 2-pass copy prefetched (32 bytes step) : 2754.1 MB/s
NEON unrolled 2-pass copy prefetched (64 bytes step) : 2853.6 MB/s
NEON fill : 6181.3 MB/s
NEON fill backwards : 6179.2 MB/s
VFP copy : 3552.2 MB/s
VFP 2-pass copy : 2661.3 MB/s
ARM fill (STRD) : 6181.4 MB/s
ARM fill (STM with 8 registers) : 6182.9 MB/s
ARM fill (STM with 4 registers) : 6181.0 MB/s
ARM copy prefetched (incr pld) : 3510.1 MB/s
ARM copy prefetched (wrap pld) : 3505.1 MB/s
ARM 2-pass copy prefetched (incr pld) : 2663.7 MB/s
ARM 2-pass copy prefetched (wrap pld) : 2669.5 MB/s (0.1%)
==========================================================================
== Framebuffer read tests. ==
== ==
== Many ARM devices use a part of the system memory as the framebuffer, ==
== typically mapped as uncached but with write-combining enabled. ==
== Writes to such framebuffers are quite fast, but reads are much ==
== slower and very sensitive to the alignment and the selection of ==
== CPU instructions which are used for accessing memory. ==
== ==
== Many x86 systems allocate the framebuffer in the GPU memory, ==
== accessible for the CPU via a relatively slow PCI-E bus. Moreover, ==
== PCI-E is asymmetric and handles reads a lot worse than writes. ==
== ==
== If uncached framebuffer reads are reasonably fast (at least 100 MB/s ==
== or preferably >300 MB/s), then using the shadow framebuffer layer ==
== is not necessary in Xorg DDX drivers, resulting in a nice overall ==
== performance improvement. For example, the xf86-video-fbturbo DDX ==
== uses this trick. ==
==========================================================================
NEON read (from framebuffer) : 804.8 MB/s
NEON copy (from framebuffer) : 384.2 MB/s
NEON 2-pass copy (from framebuffer) : 395.6 MB/s
NEON unrolled copy (from framebuffer) : 534.0 MB/s
NEON 2-pass unrolled copy (from framebuffer) : 565.0 MB/s
VFP copy (from framebuffer) : 534.1 MB/s
VFP 2-pass copy (from framebuffer) : 563.7 MB/s
ARM copy (from framebuffer) : 385.2 MB/s
ARM 2-pass copy (from framebuffer) : 380.1 MB/s
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can't handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
==========================================================================
block size : single random read / dual random read
1024 : 0.1 ns / 0.1 ns
2048 : 0.1 ns / 0.1 ns
4096 : 0.1 ns / 0.0 ns
8192 : 0.0 ns / 0.1 ns
16384 : 0.2 ns / 0.0 ns
32768 : 0.2 ns / 0.1 ns
65536 : 5.1 ns / 8.6 ns
131072 : 7.7 ns / 11.9 ns
262144 : 9.4 ns / 13.3 ns
524288 : 11.0 ns / 13.9 ns
1048576 : 21.7 ns / 31.9 ns
2097152 : 81.7 ns / 121.7 ns
4194304 : 116.2 ns / 153.5 ns
8388608 : 136.4 ns / 169.0 ns
16777216 : 147.3 ns / 176.1 ns
33554432 : 153.4 ns / 179.5 ns
67108864 : 157.0 ns / 180.7 ns
CoreELEC:~/downloads # taskset -c 0-1 ./tinymembench
tinymembench v0.4 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for 'copy' tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source -> L1 cache, L1 cache -> destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
==========================================================================
C copy backwards : 1750.7 MB/s
C copy backwards (32 byte blocks) : 1649.3 MB/s (1.9%)
C copy backwards (64 byte blocks) : 1749.7 MB/s
C copy : 1751.5 MB/s
C copy prefetched (32 bytes step) : 1891.0 MB/s (0.3%)
C copy prefetched (64 bytes step) : 1888.6 MB/s
C 2-pass copy : 1343.7 MB/s
C 2-pass copy prefetched (32 bytes step) : 1207.5 MB/s
C 2-pass copy prefetched (64 bytes step) : 1227.9 MB/s
C fill : 6664.8 MB/s
C fill (shuffle within 16 byte blocks) : 6665.4 MB/s
C fill (shuffle within 32 byte blocks) : 5330.5 MB/s
C fill (shuffle within 64 byte blocks) : 1822.6 MB/s
---
standard memcpy : 1698.5 MB/s (0.6%)
standard memset : 7156.4 MB/s
---
NEON read : 2316.5 MB/s (0.4%)
NEON read prefetched (32 bytes step) : 3927.8 MB/s
NEON read prefetched (64 bytes step) : 3929.5 MB/s
NEON read 2 data streams : 2048.5 MB/s
NEON read 2 data streams prefetched (32 bytes step) : 3622.9 MB/s
NEON read 2 data streams prefetched (64 bytes step) : 3623.2 MB/s
NEON copy : 1775.2 MB/s (0.2%)
NEON copy prefetched (32 bytes step) : 1923.2 MB/s
NEON copy prefetched (64 bytes step) : 1929.0 MB/s
NEON unrolled copy : 1788.3 MB/s (0.2%)
NEON unrolled copy prefetched (32 bytes step) : 2052.4 MB/s
NEON unrolled copy prefetched (64 bytes step) : 2050.8 MB/s
NEON copy backwards : 1764.2 MB/s (0.1%)
NEON copy backwards prefetched (32 bytes step) : 1890.0 MB/s (0.1%)
NEON copy backwards prefetched (64 bytes step) : 1881.9 MB/s
NEON 2-pass copy : 1625.2 MB/s
NEON 2-pass copy prefetched (32 bytes step) : 1729.4 MB/s
NEON 2-pass copy prefetched (64 bytes step) : 1730.5 MB/s
NEON unrolled 2-pass copy : 1574.6 MB/s
NEON unrolled 2-pass copy prefetched (32 bytes step) : 1859.0 MB/s
NEON unrolled 2-pass copy prefetched (64 bytes step) : 1933.0 MB/s
NEON fill : 7167.2 MB/s
NEON fill backwards : 7166.4 MB/s
VFP copy : 1789.6 MB/s
VFP 2-pass copy : 1599.3 MB/s
ARM fill (STRD) : 4921.2 MB/s
ARM fill (STM with 8 registers) : 7158.3 MB/s
ARM fill (STM with 4 registers) : 7013.1 MB/s
ARM copy prefetched (incr pld) : 1924.7 MB/s
ARM copy prefetched (wrap pld) : 1875.5 MB/s
ARM 2-pass copy prefetched (incr pld) : 1639.8 MB/s
ARM 2-pass copy prefetched (wrap pld) : 1635.4 MB/s
==========================================================================
== Framebuffer read tests. ==
== ==
== Many ARM devices use a part of the system memory as the framebuffer, ==
== typically mapped as uncached but with write-combining enabled. ==
== Writes to such framebuffers are quite fast, but reads are much ==
== slower and very sensitive to the alignment and the selection of ==
== CPU instructions which are used for accessing memory. ==
== ==
== Many x86 systems allocate the framebuffer in the GPU memory, ==
== accessible for the CPU via a relatively slow PCI-E bus. Moreover, ==
== PCI-E is asymmetric and handles reads a lot worse than writes. ==
== ==
== If uncached framebuffer reads are reasonably fast (at least 100 MB/s ==
== or preferably >300 MB/s), then using the shadow framebuffer layer ==
== is not necessary in Xorg DDX drivers, resulting in a nice overall ==
== performance improvement. For example, the xf86-video-fbturbo DDX ==
== uses this trick. ==
==========================================================================
NEON read (from framebuffer) : 66.3 MB/s
NEON copy (from framebuffer) : 64.8 MB/s
NEON 2-pass copy (from framebuffer) : 65.3 MB/s
NEON unrolled copy (from framebuffer) : 64.2 MB/s
NEON 2-pass unrolled copy (from framebuffer) : 64.9 MB/s
VFP copy (from framebuffer) : 397.7 MB/s
VFP 2-pass copy (from framebuffer) : 396.3 MB/s
ARM copy (from framebuffer) : 222.0 MB/s
ARM 2-pass copy (from framebuffer) : 223.2 MB/s
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can't handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
==========================================================================
block size : single random read / dual random read
1024 : 0.0 ns / 0.0 ns
2048 : 0.0 ns / 0.0 ns
4096 : 0.0 ns / 0.0 ns
8192 : 0.0 ns / 0.0 ns
16384 : 0.0 ns / 0.0 ns
32768 : 0.0 ns / 0.0 ns
65536 : 3.6 ns / 6.1 ns
131072 : 5.5 ns / 8.5 ns
262144 : 7.4 ns / 10.8 ns
524288 : 69.8 ns / 108.4 ns
1048576 : 106.8 ns / 143.5 ns
2097152 : 125.9 ns / 155.5 ns
4194304 : 139.3 ns / 163.9 ns
8388608 : 146.6 ns / 168.6 ns
16777216 : 151.1 ns / 171.8 ns
33554432 : 154.0 ns / 174.3 ns
67108864 : 166.3 ns / 195.4 ns
A73 core
Summary
CoreELEC:~/downloads # taskset -c 2-5 ./tinymembench
tinymembench v0.4 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for 'copy' tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source -> L1 cache, L1 cache -> destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
==========================================================================
C copy backwards : 3522.2 MB/s
C copy backwards (32 byte blocks) : 3518.0 MB/s
C copy backwards (64 byte blocks) : 3524.3 MB/s
C copy : 3540.1 MB/s
C copy prefetched (32 bytes step) : 3478.1 MB/s
C copy prefetched (64 bytes step) : 3524.1 MB/s
C 2-pass copy : 2688.4 MB/s (0.5%)
C 2-pass copy prefetched (32 bytes step) : 2675.3 MB/s
C 2-pass copy prefetched (64 bytes step) : 2711.8 MB/s
C fill : 6502.1 MB/s
C fill (shuffle within 16 byte blocks) : 6497.3 MB/s
C fill (shuffle within 32 byte blocks) : 6494.2 MB/s
C fill (shuffle within 64 byte blocks) : 6495.2 MB/s
---
standard memcpy : 3534.7 MB/s
standard memset : 6192.3 MB/s
---
NEON read : 7807.8 MB/s
NEON read prefetched (32 bytes step) : 7758.5 MB/s
NEON read prefetched (64 bytes step) : 7803.8 MB/s
NEON read 2 data streams : 7605.1 MB/s
NEON read 2 data streams prefetched (32 bytes step) : 7450.7 MB/s (0.3%)
NEON read 2 data streams prefetched (64 bytes step) : 7556.9 MB/s
NEON copy : 3557.3 MB/s
NEON copy prefetched (32 bytes step) : 3509.2 MB/s
NEON copy prefetched (64 bytes step) : 3545.6 MB/s
NEON unrolled copy : 3557.7 MB/s
NEON unrolled copy prefetched (32 bytes step) : 3302.3 MB/s (0.3%)
NEON unrolled copy prefetched (64 bytes step) : 3412.2 MB/s (0.2%)
NEON copy backwards : 3533.4 MB/s
NEON copy backwards prefetched (32 bytes step) : 3489.3 MB/s
NEON copy backwards prefetched (64 bytes step) : 3524.2 MB/s
NEON 2-pass copy : 3140.6 MB/s
NEON 2-pass copy prefetched (32 bytes step) : 2976.1 MB/s
NEON 2-pass copy prefetched (64 bytes step) : 2993.3 MB/s
NEON unrolled 2-pass copy : 3136.8 MB/s
NEON unrolled 2-pass copy prefetched (32 bytes step) : 2803.4 MB/s
NEON unrolled 2-pass copy prefetched (64 bytes step) : 2906.6 MB/s
NEON fill : 6188.0 MB/s
NEON fill backwards : 6181.9 MB/s
VFP copy : 3558.3 MB/s
VFP 2-pass copy : 2671.0 MB/s
ARM fill (STRD) : 6193.2 MB/s
ARM fill (STM with 8 registers) : 6190.8 MB/s
ARM fill (STM with 4 registers) : 6192.4 MB/s
ARM copy prefetched (incr pld) : 3515.0 MB/s
ARM copy prefetched (wrap pld) : 3509.1 MB/s
ARM 2-pass copy prefetched (incr pld) : 2681.7 MB/s
ARM 2-pass copy prefetched (wrap pld) : 2686.5 MB/s (0.2%)
==========================================================================
== Framebuffer read tests. ==
== ==
== Many ARM devices use a part of the system memory as the framebuffer, ==
== typically mapped as uncached but with write-combining enabled. ==
== Writes to such framebuffers are quite fast, but reads are much ==
== slower and very sensitive to the alignment and the selection of ==
== CPU instructions which are used for accessing memory. ==
== ==
== Many x86 systems allocate the framebuffer in the GPU memory, ==
== accessible for the CPU via a relatively slow PCI-E bus. Moreover, ==
== PCI-E is asymmetric and handles reads a lot worse than writes. ==
== ==
== If uncached framebuffer reads are reasonably fast (at least 100 MB/s ==
== or preferably >300 MB/s), then using the shadow framebuffer layer ==
== is not necessary in Xorg DDX drivers, resulting in a nice overall ==
== performance improvement. For example, the xf86-video-fbturbo DDX ==
== uses this trick. ==
==========================================================================
NEON read (from framebuffer) : 804.8 MB/s
NEON copy (from framebuffer) : 384.6 MB/s
NEON 2-pass copy (from framebuffer) : 395.7 MB/s
NEON unrolled copy (from framebuffer) : 534.1 MB/s
NEON 2-pass unrolled copy (from framebuffer) : 565.1 MB/s
VFP copy (from framebuffer) : 534.0 MB/s
VFP 2-pass copy (from framebuffer) : 563.9 MB/s
ARM copy (from framebuffer) : 385.6 MB/s
ARM 2-pass copy (from framebuffer) : 380.3 MB/s
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can't handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
==========================================================================
block size : single random read / dual random read
1024 : 0.0 ns / 0.0 ns
2048 : 0.0 ns / 0.0 ns
4096 : 0.0 ns / 0.0 ns
8192 : 0.1 ns / 0.0 ns
16384 : 0.1 ns / 0.0 ns
32768 : 0.0 ns / 0.0 ns
65536 : 5.1 ns / 8.5 ns
131072 : 7.6 ns / 11.8 ns
262144 : 9.4 ns / 13.3 ns
524288 : 11.0 ns / 13.8 ns
1048576 : 20.5 ns / 29.9 ns
2097152 : 81.6 ns / 121.7 ns
4194304 : 116.1 ns / 153.4 ns
8388608 : 136.3 ns / 169.0 ns
16777216 : 147.2 ns / 175.9 ns
33554432 : 153.4 ns / 179.6 ns
67108864 : 157.0 ns / 180.8 ns
I had previously used lmbench, to measure the L1-L2-RAM latency. It’s more flexible in how the latency is tested, and I could see occasional cache misses with it. There was no difference with lmbench either looking at latency.
From that I assume that A53 and A73 cores use their respective unified L2 caches regardless of what’s in the DTB. My guess is that L2 cache handling is baked into the SOC, and it’s just a question of whether the extra DTB cache information affects how the kernel assigns work between the two CPU clusters?
I see the C copy/fill speed being vastly different between A53/73 (especially 64 byte)
With DMIPS MHz and cache_not_shared the process gets assigned to the best possible core.
If the process gets bumped to A73 when we are using UI it will benefit from vastly superior RAM bandwidth. This may be the reason for perceived speed during UI. I am now learning about cache hot buddy and cache next buddy… seeing if we can keep a process on the same cluster to increase cache hits, unless there’s cache coherency between clusters…
When I navigate the UI, unless I’m just moving one or two key touches, top shows that the A73 cores are being engaged pretty soon after I start navigating. I’m primarily using Arctic Zyphr Reloaded. It’s not too heavy, has transitioning TV/Movie art, and that’s enough that I see A73 workloads.
Altering the capacity-dmips-mhz ratio might shift the balance of work to the A73 cores for smaller loads.
First I’d try putting the A53 cores offline, to see how the CE UI feels running on only A73 cores, to determine if it feels faster. CoreELEC:~ #echo 0 > /sys/devices/system/cpu/cpu0/online CoreELEC:~ #echo 0 > /sys/devices/system/cpu/cpu1/online
If that doesn’t feel faster, then I don’t know if any of this makes a difference.
Thanks for sharing the results.
So far, i see no differences for A53 cores: 32K/32K L1, 256K L2
Interestingly, there is also no difference for A73 cores: 32K/64K L1, 1024K L2
In both cases, the caches are effective in their given sizes.
Memory performance is also the same.
So seems all the optimization was placebo, and we have been fooled by wrong lscpu report?
Or is there a difference in task scheduling, as lscpu/kernel is now aware of cache sizes?!?
Regarding Memory Bandwith:
Report shows 7156 MB/s, we have x32 bus, so we have 1789MT/s => I/O-clk 894,5MHz
Regarding lmbench, can you share binary and results?
This is just my observation so far. The kernel is now aware of “non-shared” cache between cluster0 and cluster1. It is more hesitant to bump processes between the two clusters.
The idle sibling of an A73 is not an A53 anymore. If for e.g. CPU3 got a hardware interrupt and scheduler wants to move the process, it will move to CPU2,4,5.
Consequently the idle sibling of A53 is not an A73 anymore. If one got unlucky and got their process assigned to A53 then it will stay within A53 unless extra CPU cycles are needed.
Idle sibling could also be based on cluster0 vs cluster1 but the function cpus_share_cache() is a boolean function in kernel scheduler core.c and that impacts the cost analysis of bumping processes out of non shared CPU. UNLESS that function is not used at all by our kernel scheduler.
1789 MT/s is close to the 1800 MT/s that A53 reports as maximum for its DDR controller.
@YadaYada I did the test of turning off A53 and saw that CE UI is very responsive.
@rho-bot I am still willing to stand by my original suspicion that :
With this CE UI responsiveness I think we should change the dmips value in-line with the benchmark result of 33%-67% ratio. It’ll make the scheduler utilize A73 even more than now. Maybe we run 1-2 C hotter but we gain a lot in CE UI responsiveness.
EAS scheduling isn’t going to save any power when we are running performance governor. That energy dtsi is not used at all because we are not chaging CPU_FREQ.
C Copy benchmark tests are a ratio of 2. A53 = ~2100 MB/s and A73 = ~4500 MB/s. Standard memcpy is also a ratio of 2x.
memcpy() is also highly utilized funciton. ffmpeg utilizes so many memcpy() and I see that my benchmark has a 2x difference in memcpy.
A53 = ~2000 MB/s A73 = 4500 MB/s
Therefore when I turned off A53 cores the UI responsiveness was higher. Most likely effect is memory bandwidth is doubled in standard memcpy function when kodi isn’t allowed to run on A53.
A53 Memory Test
tinymembench v0.4.9 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for ‘copy’ tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source → L1 cache, L1 cache → destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
C copy backwards : 2103.9 MB/s (0.3%)
C copy backwards (32 byte blocks) : 2052.4 MB/s (1.1%)
C copy backwards (64 byte blocks) : 2043.1 MB/s (0.9%)
C copy : 2063.7 MB/s (0.3%)
C copy prefetched (32 bytes step) : 2242.7 MB/s
C copy prefetched (64 bytes step) : 2248.0 MB/s (0.1%)
C 2-pass copy : 1687.7 MB/s
C 2-pass copy prefetched (32 bytes step) : 1786.0 MB/s (0.2%)
C 2-pass copy prefetched (64 bytes step) : 1809.4 MB/s
C fill : 7371.6 MB/s
C fill (shuffle within 16 byte blocks) : 7372.7 MB/s (0.2%)
C fill (shuffle within 32 byte blocks) : 7370.8 MB/s
C fill (shuffle within 64 byte blocks) : 7366.4 MB/s
standard memcpy : 2036.6 MB/s (0.6%)
standard memset : 4736.2 MB/s
ARM fill (STM with 8 registers) : 7357.7 MB/s
ARM fill (STM with 4 registers) : 6986.2 MB/s (0.2%)
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can’t handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
tinymembench v0.4.9 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for ‘copy’ tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source → L1 cache, L1 cache → destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
C copy backwards : 4512.9 MB/s
C copy backwards (32 byte blocks) : 4512.8 MB/s
C copy backwards (64 byte blocks) : 4514.3 MB/s
C copy : 4522.0 MB/s
C copy prefetched (32 bytes step) : 4499.1 MB/s
C copy prefetched (64 bytes step) : 4523.2 MB/s
C 2-pass copy : 3056.9 MB/s
C 2-pass copy prefetched (32 bytes step) : 2819.6 MB/s (0.1%)
C 2-pass copy prefetched (64 bytes step) : 2855.2 MB/s (0.1%)
C fill : 8957.6 MB/s
C fill (shuffle within 16 byte blocks) : 8973.3 MB/s (0.1%)
C fill (shuffle within 32 byte blocks) : 8958.7 MB/s (0.1%)
C fill (shuffle within 64 byte blocks) : 8964.0 MB/s (0.2%)
standard memcpy : 4502.1 MB/s
standard memset : 8962.6 MB/s (0.1%)
ARM fill (STM with 8 registers) : 8950.8 MB/s
ARM fill (STM with 4 registers) : 8963.7 MB/s
==========================================================================
== Memory latency test ==
== ==
== Average time is measured for random memory accesses in the buffers ==
== of different sizes. The larger is the buffer, the more significant ==
== are relative contributions of TLB, L1/L2 cache misses and SDRAM ==
== accesses. For extremely large buffer sizes we are expecting to see ==
== page table walk with several requests to SDRAM for almost every ==
== memory access (though 64MiB is not nearly large enough to experience ==
== this effect to its fullest). ==
== ==
== Note 1: All the numbers are representing extra time, which needs to ==
== be added to L1 cache latency. The cycle timings for L1 cache ==
== latency can be usually found in the processor documentation. ==
== Note 2: Dual random read means that we are simultaneously performing ==
== two independent memory accesses at a time. In the case if ==
== the memory subsystem can’t handle multiple outstanding ==
== requests, dual random read has the same timings as two ==
== single reads performed one after another. ==
It may be that adding the extra information to the DTB makes it available for the kernel, but that the kernel doesn’t actually make use of it.
Didn’t we test CPU load balancing with the software decoding. If there was a change we’d expect to see a shift in the distribution of CPU loads across the two clusters decoding lower to higher bitrate videos.
It still remains to be seen if drastically changing the capacity-dmips-mhz ratio has any effect, it may not do anything in CE-NG.
On my system, using ondemand and with conservative settings for ramping up frequency I am seeing a noticeable change in scheduler behaviour with the changes to the dtb.
Havent had the opportunity to individually test the cpu capacity and L2 cache settings yet, but did some very quick tests along these lines when first putting together the shell script to modify the dtb.
Higher values for little core cpu capacity (smaller ratio between big and little) did indeed seem to increase the utilisation of the little cores as observed by monitoring top while scrolling through a list of media listitem in the Kodi GUI, while lower values for little core cpu capacity seemed to increase the utlisation of the big cores over the little cores.
Measurement of temperature was from equal point of temperature before testing in both cases ? My skill is that temperature was better with new dtb. Try change order of both testing.